
"The difference between a $200 video and a $2 video is knowing that 80% of it doesnt need to be AI generated video at all."
Heres what nobody tells you: the channels pumping out 25-minute documentaries 3x/week are NOT generating every frame as video. This is the single biggest misconception in the AI video space and its costing people thousands of dollars a month.
I know this because I run a daily AI YouTube channel, talked to 50+ creators doing the same thing, and built an automated pipeline from scratch.
💸 The Big Misconception That's Wasting Everyone's Money
You look at these channels and think "wow they must be generating hundreds of video clips per episode." Nope.
What they're ACTUALLY doing:
- Generate 150-200 still images for the entire video
- Animate ONLY 10-20% of those for key dramatic moments
- Ken Burns effects (pan/zoom via ffmpeg) on the remaining 80-90%. This is free
- The "cinematic" feel comes from editing, not generation. Slow zooms, crossfades, good pacing with voiceover
You think you need 300 video clips. You actually need 200 images and 25 animations. Thats the difference between a $200 video and a $2 video.
Two dollars. 🤯


Smart variation I stole from a German channel called "Ungesagt": front-load your animated scenes in the first 2 minutes to hook viewers, then coast on Ken Burns for the rest. Algorithm cares about retention in the first 30-120 seconds. After that, if your voiceover is good, nobody notices. Been doing this for months and literally nobody has commented on it.
🔄 The Pipeline (Single Prompt to Finished Video)
My exact workflow - one prompt in, finished video out in ~20 minutes on a cheap laptop:
- Claude Opus 4.6 generates full script + per-scene image prompts as SSML (Speech Synthesis Markup Language). This is NOT a single prompt. More on multi-pass scripting below.
- Runware API (z image turbo) bulk generates all images. $0.003 per image. 100 images = $0.30. Thirty cents.
- Selective animation: 10-20% of images get animated via Kling or SeedDance Pro Fast. ~$0.07 per 10s clip.
- Ken Burns effects on the remaining 80-90% via ffmpeg. Free. Randomized presets. If you hardcode one motion style it looks robotic immediately.
- Cartesia for TTS voiceover.
- ElevenLabs for music generation, cached in a Pinecone vector DB. Check cosine similarity before generating new music. If something close enough exists, reuse it. Cuts audio costs from ~$150/mo to ~$40-50.
- ffmpeg assembles everything. Concat demuxer + xfade filter for transitions, audio sync, subtitle burn-in.
Total cost: ~$2 per video. One Node.js script. No Premiere. No CapCut. No dragging clips into a timeline like some kind of animal.

🧰 The Tool Stack
Scripts: Claude Opus 4.6
Not ChatGPT. Not Gemini. Claude Opus produces genuinely better narrative scripts. More texture, more natural pacing, follows complex multi-pass instructions without drifting.
ChatGPT scripts all sound the same. That overly enthusiastic, bullet-point-brained, "lets dive in" energy. You know EXACTLY what Im talking about. 🙄
TTS: Cartesia Sonic 3
~8x cheaper than ElevenLabs and the quality is close.
Key feature most people miss: emotional tags. Sonic 3 supports tags that make the voice sound excited, serious, whispering etc in different sections. A monotone AI voice is the #1 tell that content is AI generated. Varying emotional delivery makes it sound dramatically more natural.
Save ElevenLabs for music. Dont waste it on TTS.
🖼️ Images: z image turbo via Runware
$0.003 per image. Batch hundreds in parallel via API. No GPU needed.
Why not Leonardo? API consistency varies wildly between batches. People report 40%+ reject rates with Lucid Origin. My reject rate with z image turbo is around 10-15%.
Why not Midjourney? Not API-friendly for automated pipelines.
Why not Google models? They inject invisible SynthID watermarks that YouTube can detect. Massively increases your chances of being flagged. Most people dont know this. Switch immediately if youre using these.
| Tool | Cost per image | API batch support | Consistency | SynthID risk |
|---|---|---|---|---|
| Runware (z image turbo) | $0.003 | Yes, parallel | Good (10-15% reject) | None |
| Leonardo (Lucid Origin) | ~$0.01 | Yes | Poor (40%+ reject) | None |
| Midjourney | ~$0.02 | No | Excellent | None |
| Google Imagen | ~$0.005 | Yes | Good | Yes |
| DALL-E 3 | ~$0.04 | Yes | Good | None |
🎬 Animation: Kling / SeedDance Pro Fast
~$0.07 per 10s clip. Use selectively.
Kling handles subtle motion better than Wan. If you need calm scenes Kling actually listens when you ask for low motion intensity. Wan assumes everything alive should be moving aggressively, like a toddler who just discovered Red Bull.

For truly zero motion: skip video gen entirely. AI image + subtle Ken Burns. Viewers cannot tell the difference when theres voiceover holding their attention.
🎵 Music: ElevenLabs + Pinecone Cache
Nobody else is doing this:
- Generate music with ElevenLabs
- Embed audio characteristics into Pinecone
- Before generating new music, check cosine similarity against existing library
- Close enough match? Reuse it
- Only generate new tracks when nothing matches
Cut my audio costs 60-70%. Dont use the same track for every video though. YouTube flags that as repetitive content.
| Service | Use case | Cost | Quality |
|---|---|---|---|
| Cartesia Sonic 3 | TTS narration | ~8x cheaper than ElevenLabs | Near-ElevenLabs |
| ElevenLabs | Voice cloning, music | Premium | Best in class |
| Chatterbox (open source) | Local TTS | Free | Getting close |
| Fish Audio (open source) | Local voice cloning | Free | Solid |
🔨 Assembly: ffmpeg
Free. Open source. Runs on anything. People spending hours in Premiere or CapCut are doing what a script can do in seconds. 👨🍳💋

✍️ Multi-Pass Scripting (Why Your Scripts Sound Like AI)
Most impactful technique I use. Most people skip it.
Single-pass prompting (what 95% of people do): "Write me a 10-minute script about the history of Rome." Generic. Predictable. Wikipedia-rewrite energy.
Multi-pass "narrative diffusion" (what actually works):
- Pass 1, Structure: Story beats, act structure, emotional arc, hook, payoff. Just the skeleton.
- Pass 2, Narration: Voiceover text written for the ear not the eye. Short sentences. Natural rhythm.
- Pass 3, Visual descriptions: Per-scene image prompts. Camera angles, lighting, composition. Separate pass because visual thinking and narrative thinking are different skills.
- Pass 4, Polish: Cut anything that sounds AI-ish. Vary sentence length. Remove "delve". Remove "lets dive in". Remove "its worth noting". Remove every phrase that screams "a language model wrote this".

Claude Opus is particularly good at this because it holds complex multi-step instructions without drifting. GPT tends to forget earlier instructions by pass 3-4 and starts improvising. Which is a polite way of saying "making stuff up."
🎭 Character Consistency
The #1 complaint I hear from creators. And the advice online is terrible.
The Storyboard Pipeline
DO NOT generate images scene by scene. Thats where everything falls apart.
Instead:
- Generate ALL images for the entire video upfront in one batch
- Pass same character description + reference image into every prompt
- Lock seeds where possible (Runware supports this)
- Review the full batch for consistency
- Fix outliers
- THEN animate
Fundamentally different mental model. Youre making a storyboard, not going scene by scene. The moment you start generating sequentially and hoping theyll match, youve already lost.
Character Design
Simpler = more consistent. Detailed realistic faces drift like crazy. Stylized/illustrated characters stay consistent 10x better.
Reference images are mandatory. Generate one hero image of your character that you love. Pass it into every subsequent prompt.
Be absurdly specific. Dont say "a girl". Say "a 10-year-old girl with shoulder-length brown hair, blue dress with white collar, simple anime style, warm skin tone, round face, soft lighting from the left."
| Generation method | Scene 1 | Scene 2 | Scene 3 |
|---|---|---|---|
| Scene-by-scene generation |  |  |  |
| Storyboard batch generation | |  |  |
⚠️ What Gets AI Channels Demonetized
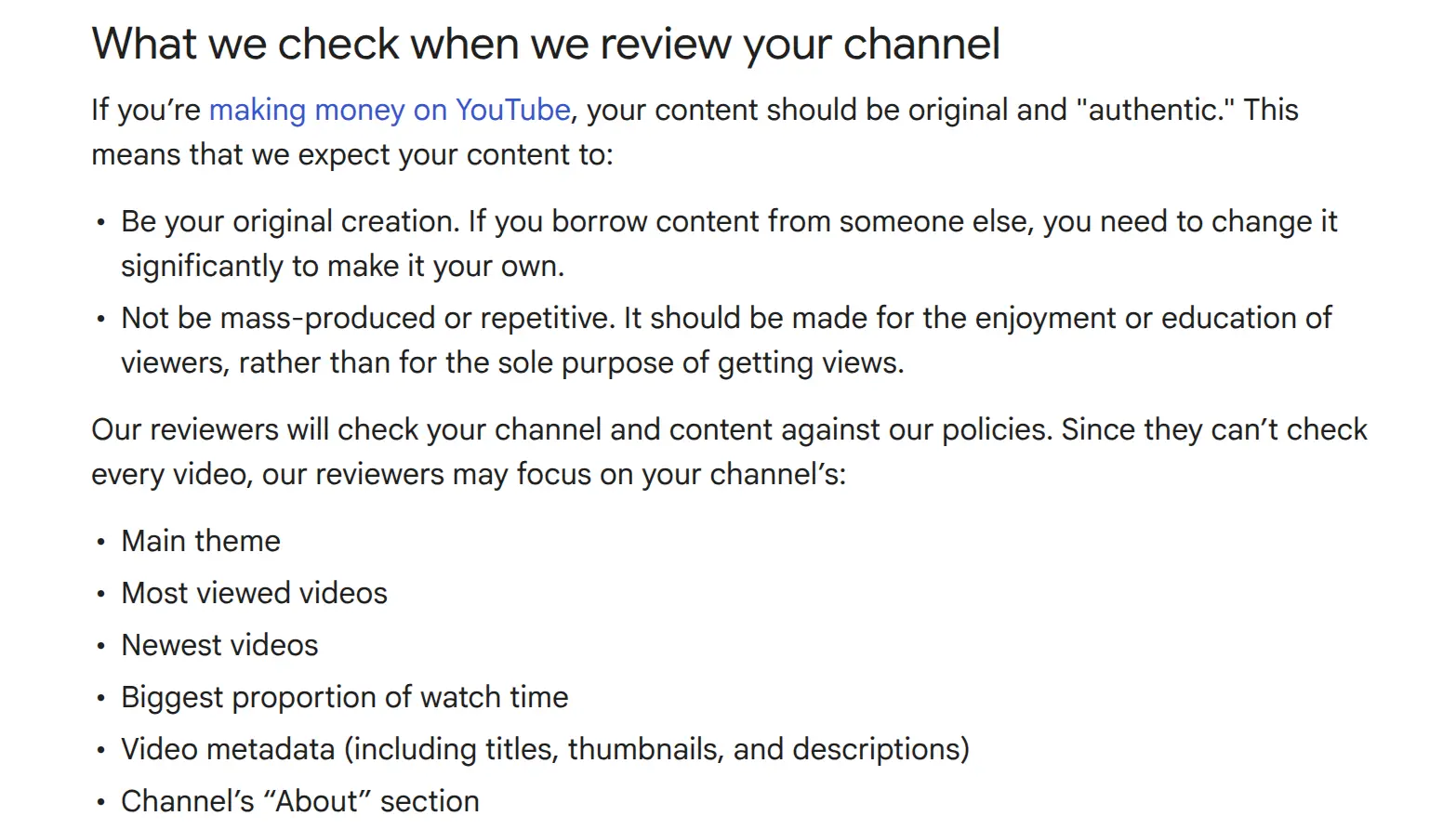
YouTube isnt cracking down on faceless AI content. Theyre cracking down on low-effort repetitive content that happens to be AI. Huge difference.
Reused Content. Copying Reddit stories, other peoples gameplay even "no copyright" stuff, regurgitating Wikipedia. YouTube flags all of it.
The Template Problem. Every video looks like it came from the same template with different words? Youre dead. Vary your editing style, transitions, pacing, color grading, music. This is why randomized Ken Burns presets matter. Theyre not aesthetic choices. Theyre survival tactics.

No Human Creative Input. YouTube wants a human directing creative decisions. Writing prompts, curating images, selecting scenes for animation, reviewing output before publishing. That counts. Document your process.
SynthID Watermarks. Google image models inject invisible watermarks YouTube can detect. Least known monetization risk. Easiest to fix. Stop using Google models.
Voice Cloning Real People. Dont. Create original AI voices.
🗑️ Why All-in-One Tools Suck
Tried them all. OpenArt, Higgsfield, AutoShorts, StoryShort, Vimerse, Vadoo, Hypernatural, Freepik. A dozen more Ive mercifully forgotten.
Nobody on r/aitubers recommends any of them. That should tell you everything.
Output quality isnt there. Customization too limited. One-size-fits-all approach. $30-100/mo for output you could produce better at $2/video calling APIs directly. And you cant see or control whats happening under the hood.
Market is split in half: expensive tools that output generic stuff, and powerful individual models that need technical skill to combine. Creators want the power of the second with the simplicity of the first.
Thats the gap. Thats why were building OpenSlop.
OpenSlop is the open-source workflow that creates ready-to-publish AI videos for free forever.
Join creators on the waitlist
⚖️ No-Code vs Code

No-Code (Make/n8n/Airtable)
Gets you ~70% there. Fine for 1-2 videos a week. Falls apart at scale. Execution limits, latency between modules, random timeouts, cant do ffmpeg, terrible error handling. At 2+ videos/day its a nightmare.
Code (Python/Node + APIs)
More reliable, cheaper, fully customizable. Retry logic, parallel processing, queueing. At 5-8 videos/day its the only option.
🤔 Cant Code?
Learn basic Python. Claude can write 90% of it for you. Youre mostly gluing API calls together. Less scary than it sounds.

Or wait for OpenSlop. Free, open source, built for exactly this.
OpenSlop is the open-source workflow that creates ready-to-publish AI videos for free forever.
Join creators on the waitlist
🎯 Bottom Line
The people making real money with AI video in 2026 arent using magical tools that dont exist yet. Theyre using the same APIs available to everyone, combined intelligently into a pipeline that costs $2 per video instead of $200.
The "secret" is that 80% of your video doesnt need to be AI generated video at all. It needs to be AI generated images with smart camera movements.
The other secret is that none of this is actually secret. Most people would just rather spend $99/month on a tool that promises to do everything than spend a weekend learning how the sausage gets made.
Your call. 🎤⬇️
